Abstract
Nowadays, Artificial Intelligence (AI) has become a popular topic in the big data era. At the same time, importance should be attached to the security and privacy problems of AI with the growth of basic data and AI using population. This essay points out the security and privacy problems in the process of programming in terms of input, training model, and output with some examples and analyses the feasible solution aiming to different threats. The result reveals that the AI should pay attention to the security and privacy issues by adding a self-testing procedure and introducing the standard of input and output data to avoid relevant security and privacy issues.
Keywords: machine learning, adversarial examples, poisoning attack, artificial intelligence security, data processing
1.Introduction
Artificial Intelligence promotes the large-scale and industrial development of machine learning. In some specific areas, Artificial intelligence (AI) could be defined as intelligence demonstrated by machines, as opposed to the natural intelligence displayed by humans or animals, and has reached or even exceeded human-level performance. However, most previous machine-learning theories fail to consider the open and even adversarial environment, and the security and privacy issues of AI are gradually increasing (Yufei Chen *et al*., 2019). This essay will review previous works on AI systems security and privacy, revealing potential security and privacy risks, and evaluating countermeasures in terms of three key components of AI systems: input, machine learning models, and output with examples and comparisons.
2.Model of AI Systems Attack Surface
2.1 Structure of AI Systems
AI systems mainly include three key areas:
i) Data Input. The definition of input data is that data used in the training and testing of the artificial neural network are usually unstructured data such as images, voice, and text that need to be recognized. AI systems obtain external environment data through sensors (microphone, camera, laser radar, GPS el.) (Barocas Solon & Andrew D Selbst, 2016).
ii) Machine Learning Model. The Machine Learning Model is the core of an AI system, similar to the human being’s brain, mainly including two processes, model training and predicting. For model training, the model is trained by massive input data and labeled data, so that the model’s output converges to be consistent with the marker data with the same input. In the process of training, the Machine Learning Model adjusts parameters using the pre-processed training data to improve working performance (usually measured by the accuracy rate, recall rate, and other indicators) aiming to achieve specific goals. Specifically, for reinforcement learning, input data could be produced from dynamic interactions between models and virtual environments. After the training process has been completed, a Machine Learning Model is entering the process of predicting. Output could be given by data input through the trained model.
iii) Output. The output result is calculated by the artificial neural network from input data. The deviation between the output data and the labeled data is used to modify the model. AI systems generate in various forms such as labels and confidence levels to support subsequent tasks such as classification and decision making.
2.2 The Vulnerability of AI Systems
So far, the standard and policy of AI systems have not been introduced publicly, which means the programming producers could revise details of their AI systems flexibly. In addition, programming producers use open-source data which could be utilized by attackers. As a result of this kind of openness of the AI system environment, the input and output links could be directly exposed to the attack threat environment. In the following parts, we will see even if the machine learning model is hidden, the attacker can still predict the internal structure of the system and launch attacks by sending polling samples.
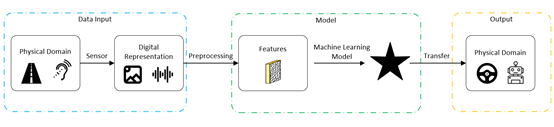
Figure 1: The basic framework of AI systems, AI systems include 3 components: Date Input, Model Training, and Output.
3.AI Security Risk and Countermeasures with Examples
3.1 Data Input Link Security Risk and Countermeasures
AI systems obtain information through sensors in various ways and adjust their forms and sizes and other attributes according to the requirement of model inputting. Attackers could pollute datasets by inserting inaccurate or incorrect data, which would lead to AI systems extracting unexpected features in the next step.
The real example of input link in AI model security risks will be demonstrated in the following section. Microsoft produced an AI chatbot named Tay which can learn on its own from the internet. It is interesting to note that Tay started doing controversial behaviors after one-day study (https://www.thepaper.cn/newsDetail_forward_1448368). The reason of Tay’s behaviors is that the input data is from the internet, and the information from the internet is not only including positive words but also negative aspects of society. Once the negative input data entering the process of training the AI model, the incorrect result will be given during the predicting process. In the same way, AI systems could be attacked by giving incorrect data in the training process since the different input data contributes to totally different results.

Figure 2: The twitter chat box of Microsoft’s Tay who studies controversial behaviors
(Image source: https://www.thepaper.cn/newsDetail_forward_1448368 )
Tay is a typical example which was attacked in the process of input. These kinds of problems are universal, and the chatbots exploited by Tencent and Microsoft also occurred similar mistakes with Tay(https://tech.sina.com.cn/n/k/2019-07-02/doc-ihytcitk9054475.shtml). These examples reflect the results of machine learning could be influenced directly by input data.
Tay’s input mistake was due to the difficulty of filtering the right input data by humans since the training process of the AI model needs massive data. The countermeasures dealing with this kind of problem is that by adding the filtering process before training, robots could filter the data and information with the same interpretations as the human being, such as 80% positive words plus 20% negative words, which could build a more similar human being’s brain for auto-chatbots. In addition, the examining process between the output and showing the results could make the limited output. This is the same as the human being’s brain, examining the words between figuring out process and speaking process. In practice, the most useful method is to self-estimate data distribution before data entered model for training. Another improvement of solving input attacks is reducing the influence of data distribution on the model.
3.2 Machine-Learning Model Link Security Risk and Countermeasures
The machine-learning model is the core part of AI systems to perceive and decide, including training processes and predicting processes. ‘Backdoor Attack’ (Gu Tianyu *et al*., 2017, Chen Xinyun et al., 2017) is a method to attack AI systems in the model link, which could be defined as the trained model could be misoriented in some specific situations by altering the feature or feature distribution of the machine learning dataset. ‘Trojan Attack’ (Liu Yingqi *et al*., 2017) is a more harmful poisoning attack, and the definition of “Trojan Attack” is that making error data or directional misleading data are mixed into the training dataset of machine learning to make the trained model generally incorrect or incorrect in some specific scenarios.
These two attacking methods could embed a ‘backdoor’ or ‘trojan’ into the model and complete malicious attacks by a simple backdoor trigger in the prediction stage. A typical example of machine-learning model security risk is demonstrated in the following text, which is about the backdoor. Deep neural networks embedded in the backdoor perform well in the normal sample but predict specific faults with input samples including the specific backdoor trigger. In the auto-driving field, Gu *et al*. (2017), generated a backdoor in a road sign recognition model by inserting a “stop” sign image with a special label (i.e. a back door trigger) into the training set and marking it as a “speed limit”. Although the model can correctly classify normal street signs, malicious stop signs with triggers could be classified incorrectly. So by executing this attack, an attacker could trick the model by using specific labels to classify any stop sign as a speed limit, thus posing a serious safety hazard to autonomous vehicles.

Figure 3: A stop sign and its backdoored versions using, from left to right, a sticker with a yellow square, a ‘bomb’, and a flower as backdoors (Gu Tianyu *et al*. (2017)).
In addition, backdoor attacks can also be used to “watermark” deep neural networks to identify models as the intellectual property of specific suppliers, so as to prevent models with the commercial value from being easily copied (Adi Yossi *et al*., 2018). The definition of the watermark is that superimposing a specific image on the original image makes different images have the same features, some of which can be observed by the naked eye, such as adding a flower in the center of the image, some are invisible to the naked eye but can be detected by machines, such as by superimposing a specific gaussian noise on an image. Although their method makes the watermark resistant to destruction and guarantees the high recognition accuracy of the model, it does not clearly solve the issue of false claim of ownership, nor does it clearly consider the attack resistance of the watermark generation algorithm after it is exposed. Backdoor attack detection is a vital but challenging way to avoid the existent of backdoor attackers since the only attackers knew the specific triggers which can cause malicious behavior. To solve this challenge, Chen *et al*. (2018), proposed activation clustering (AC) method to examine the training sample embedded in the backdoor trigger. The AC method estimates whether the model attacked and whether the data sample is malicious by analyzing the neural network activation condition of training data. Besides, Wang *et al*. (2019), proposed a detection system for the backdoor attack of deep neural networks by using input-filtering, neuronal-pruning, and unlearning methods in 2019. This detection system could identify whether the model attacked and rebuild possible backdoors trigger to ensure security during the process of applying the model. Their studies utilized diverse ways to promote the detection of the backdoor and improve the model security aiming to the backdoor. The clustering method could be used to identify backdoor when the dataset with accessibility, the input-filtering method could be used to deal with the dataset which is accessed difficultly. It is noted that a combination of the clustering method and input-filter method could avoid backdoors attack efficiently since the clustering method can filter the abnormal data and the input-filtering can reduce the influence of abnormal data.
3.3 Output Link Security Risk and Countermeasures
Output could decide the classification and decision-making of Artificial Intelligence systems directly by tampering or hijacking outputted results. In the auto-driving field, the driving actions identified by the AI systems should be uploaded to the controllers of cars, and attackers could hijack or tamper during the period of uploading. In this case, the auto-driving system will be out of order which will let controllers of the cars acquire wrong decisions and lead to huge economic loss. In this way, the period of uploading between the AI systems and controllers should be paid attention to guarantee security from attackers. The solution to this kind of security risk is that adding the estimation process after the instructions uploading from the AI systems entering controllers, which can guarantee the safety of drivers and property though the instructions have been hijacked or tampered with. The aim of adding an estimation process is to avoid potential traffic accidents. In other words, the drivers and property will be never threatened instead of depending on the accepted instruction. For AI systems, we must concern estimating and limiting the results, which will improve the security index and avoid the frequency of accidents.
4.Conclusion
The security and privacy of the AI model have become a promising research field with the further development of machine learning technology and the application scene of the AI model increase gradually in recent years. Nowadays, the machine learning model has attracted a wide interest of scholars from academia and industry and in-depth research has been applied and made many research achievements in various areas. So far, however, the security and privacy protection of the AI model is in the primary stage since the relevant standards have not been published and companies do not have unified data sources. The aim of this essay is to re-examine and analyze the source of security threats and subsistent examples in the development and application of machine learning, clarify the advantages and disadvantages of the existing application and technology, and clarify the trends of further AI models. At the same time, many key scientific problems are waiting to be solved as human-being have not found out the fundamental mechanism of the AI model.
This essay systematically studies the security and privacy issues of AI models in terms of input, model, output respectively with examples and respond solutions, and scientifically classifies, summarizes, and analyses the related research. In addition, this essay discusses the accessible research direction in the future and points out the current challenges in the study of machine learning model security and privacy protection which could promote the standards of further development and application of machine learning model security and privacy research and make more researchers attach importance to this kind of issue instead of structuring model only.
Reference
Adi, Yossi, et al. “Turning your weakness into a strength: Watermarking deep neural networks by backdooring.” *27th {USENIX} Security Symposium ({USENIX} Security 18)*. 2018.
Barocas, Solon, and Andrew D. Selbst. “Big data’s disparate impact.” *Calif. L. Rev.* 104 (2016): 671.
Chen, Bryant, et al. “Detecting backdoor attacks on deep neural networks by activation clustering.” *arXiv preprint arXiv:1811.03728* (2018).
Chen, Xinyun, et al. “Targeted backdoor attacks on deep learning systems using data poisoning.” *arXiv preprint arXiv:1712.05526* (2017).
Gu, Tianyu, Brendan Dolan-Gavitt, and Siddharth Garg. “Badnets: Identifying vulnerabilities in the machine learning model supply chain.” *arXiv preprint arXiv:1708.06733* (2017).
(https://tech.sina.com.cn/n/k/2019-07-02/doc-ihytcitk9054475.shtml)
(https://www.thepaper.cn/newsDetail_forward_1448368)
Ji, Shou Ling, et al. “ Translated title of the contribution: Security and Privacy of Machine Learning Models.” *Ruan Jian Xue Bao/Journal of Software* 32.1 (2021): 41-67.
Liu, Yingqi, et al. “Trojaning attack on neural networks.” (2017).
Wang, Bolun, et al. “Neural cleanse: Identifying and mitigating backdoor attacks in neural networks.” *2019 IEEE Symposium on Security and Privacy (SP)*. IEEE, 2019.
Yufei, Chen, et al. “Security and privacy risks in artificial intelligence systems.” *Journal of Computer Research and Development* 56.10 (2019): 2135.